16.1 메모리 계층(Memory Hierarchy)
16.1-1 메모리 계층 구조
Note) 하드 디스크와 메인 메모리를 같은 관점으로 봐야함.
- 하드 디스크에는 저장이라는 기능이 있음. 즉 비휘발성 메모리. 파워를 꺼도 날아가지 않음.
그리고 실행의 기능도 있음. 그러나 메모리는 저장 기능은 없고 실행의 기능만 있음.
- 익히들 하드디스크를 배울 때는 저장 관점으로,
메모리를 배울 때는 실행 관점으로 배움. 그러나 이 챕터에서만큼은 둘 다 실행의 관점.
즉, 메모리 매니지먼트는 실행의 관점에서 배우는 파트. 저장은 File system 파트.
이 파트를 배울때는 저장의 관점에 너무 매몰되면 안됨. 그렇다고 저장 관점이 아에 필요없진 않음.
Note) 메모리 계층 구조의 필요성
- 컴퓨터를 직접 만든다고 가정 해 보자. 일단 그럼 CPU와 메인 메모리를 사옴.
CPU는 메인 메모리에서 데이터를 가져다가 연산하고 그 결과를 메인 메모리에 저장.
- 근데 시장에 신상품이 나옴. 이름은 캐시. 기존의 메인 메모리보다 훨씬 빠르나, 단가가 비쌈.
기존에 쓰던 메인 메모리를 캐시로 싹 교체하고 싶으나, 여의치 않음.
메인 메모리는 50MB나 되고, 지금 돈으로는 캐시를 2MB 밖에 못삼.
- 그렇게 포기하고, 프로그램이 어떤 특성을 갖는지 살펴보게됨.
잘 살펴보았더니, 메모리의 특정 부분을 중구난방 접근하는게 아니라
어떤 곳을 실행하면 높은 확률로 그 지역 근방 메모리를 접근함.
중간에 먼 곳으로 점프해서 접근하긴하나, 또 다시 그 지역 근방 메모리를 접근.
즉, 지역적인 특성을 가짐.(함수와 비슷한 느낌.)
- 그러니, 캐시를 2MB만 사서 CPU와 메인 메모리의 중간에 두자.
그리고 메인 메모리를 캐시 크기만큼 블럭 단위로 나누자. 25블럭이 나옴.
캐시는 연산이 빠르다고 하니까, 메인 메모리에서 현재 실행 중인 메모리 블럭만
올려와서 캐시를 통해 CPU가 연산하게끔 하자. -> 메모리 계층의 등장.
- 이제 또 시장에 신상품이 나옴. 슈퍼 캐시 등장. 똑같이 메모리 계층 개념 적용.
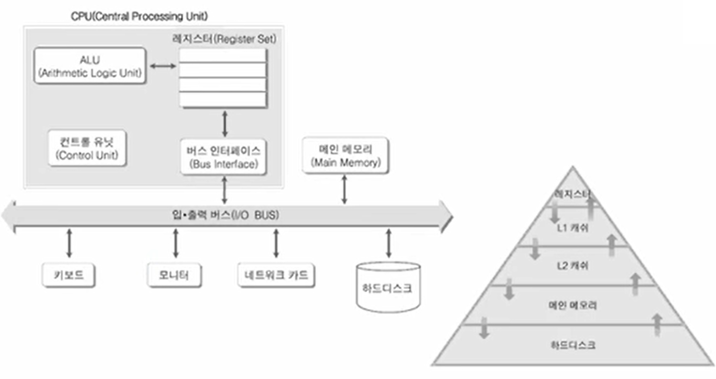
그래서 아래 그림 중 피라미드 그림에서, 실행의 관점으로 보면 서로서로의 관계가
모두다 일치함. 하드 디스크 입장에서 메인 메모리는 캐시. 하드 디스크에는 지금
실행에 필요한 모든게 있지만, 곧바로 CPU에 전달하지 않고 블럭 단위로 메인 메모리에 올려줌.
메인 메모리 입장에서 L2캐시는 "캐시". 마찬가지로 메인 메모리는 CPU가 자기보다 더 빠르게
접근할 수 있는 L2캐시에 데이터를 블럭 단위로 밀어 올림. 그래서 각 이름들을 별도로 공부할 필요 없음.
Note) 메모리 계층 구조의 원리
- CPU는 메인 메모리에게 데이터를 요청함.
메인 메모리가 갖고 있다면, 곧바로 CPU에게 주지만 없으면 하드 디스크에 요청함.
그럼 하드 디스크는 그 데이터 블럭을 메인 메모리에게 밀어 올려줌.
그래서 메인 메모리는 CPU에게 데이터를 넘겨줌.
- 피라미드 그림 상으로 보면, ALU가 L1 캐시에 데이터를 요청함. (레지스터가 아님.)
L1 캐시가 갖고 있지 않으면 L1 캐시는 L2 캐시에게 요청함.
L2 캐시가 갖고 있지 않으면 메인 메모리에게 요청함.
메인 메모리에게 없으면 하드 디스크에게 요청함.
하드 디스크가 있으면 메인 메모리에 데이터를 올려주고, ... 반복하다가
L1 캐시가 L2 캐시에게 전달받은 메모리를 레지스터에 밀어올림.
- 근데 이럴거면, CPU에서 하드디스크로 바로 접근하는게 더 빠른거 아닐까 싶음.
만약 프로그램의 실행 흐름이 굉장히 산발적이라면 맞는 말.
그러나 지역적인 특성이 강하기 때문에, 메모리 계층 구조가 더 성능향상에 올바른 구조.
16.2 캐시(Cache)와 캐시 알고리듬
Prologue) 이번 파트의 중요한 키워드는 지역성(Locality).
프로그램의 실행에 필요한 전체 메모리가 있다고 가정 해 보자.
이 메모리의 시작과 끝이 있다면, 그 사이를 산발적으로 랜덤하게 접근하지않음.
한 곳을 접근했으면 그 다음에는 그 근처를 접근하게 될 확률이 상당히 높다.
즉, 프로그램의 메모리 접근 흐름은 지역성을 지닌다.
Note) 근데 내가 억지로 산발적인 메모리 접근이 발생하게끔 코딩한다면?
세상에 모든 코드 중 임의의 코드는 산발적인 메모리 접근이 발생하지 않을까?
거의 모든 프로그램은 지역성을 지님. 즉, 프로그램이라 함은 지역성을 지니게됨.
언어가 그렇게 디자인 되어 있고, 프로그램이라는 개념이 그렇게 디자인 되어 있음.
지역성을 아에 무시할 수 없음. 어느정도냐면, CPU가 캐시에게 A 데이터가 있냐고
물었을 때 있을 확률이 90퍼가 넘음.(어떻게 이렇게 높은지도 이후에 설명 함.)
그래서 컴퓨터 요소 중, 캐시의 용량이 아주 중요함.
Note) 그럼 좋은 프로그램이라 함은, 지역성이 높아서 캐시를 자주 사용하게끔 짜여진 걸까?
일반적으로 지역성을 신경쓰지 않은 프로그램과 상당히 신경쓴 프로그램의 차이는 미미함.
그러나, 인코딩 프로그램같이 데이터를 순차적으로 가져다 써야하는 프로그램의 경우는 다름.
임베디드 개발에서도 지역성의 고려는 중요해짐.
16.2-1 프로그램의 일반적 특성
Note) 성능 향상과 캐시 메모리
프로그램의 Locality 때문에, 캐시 메모리의 유무는 성능 향상에 영향을 끼친다.
Note) 캐시 메모리의 두 가지 Locality 개념
- Temporal Locality: 반복 접근
ex. int nSum이라는 변수를 선언하면, 이 변수에 접근할 확률이 높다.
- Spatial Locality: 주변 접근.
ex. int num1, num2라고 변수를 선언했을 때, num1에 접근하고나면
num2에도 접근할 확률이 높다.
16.2-2 프로그램 상에서의 Locality
Note)
void BubbleSort(int srcArr[], int n)
{
int i, j, temp; // Temporal Locality
for (i = 0; i < n; ++i)
{
for (j = i + 1; j < n - 1; ++j)
{
if (srcArr[j] < srcArr[j - 1])
{
temp = srcArr[j - 1];
srcArr[j - 1] = temp; // Spatial Locality
srcArr[j] = temp;
}
}
}
}
16.2-3 캐시 알고리듬
Note) 캐시 기본 정책
- 캐시 특성: Temporal Locality
- 블럭 단위 전송: Spatial Locality
CPU가 캐시에 특정 데이터 유무를 물었을때, 있을 확률이 90퍼인 이유는
주변 접근 특성 때문임.
Note) CPU가 0x100번지의 1byte 크기 데이터가 필요하다고 할때, 전개되는 시나리오.
- 레지스터와 L1 캐시 사이의 전송 단위가 있음.(ex. 32bit)
- L1 캐시와 L2 캐시 사이의 전송 단위가 있음.(ex. 2MB)
- L2 캐시와 메인 메모리 사이의 전송 단위가 있음.(ex. 5MB)
- 메인 메모리와 하드디스크 사이의 전송 단위가 있음.(ex. 10MB)
- 당연히 메인 메모리와 하드디스크 사이의 데이터 전송 속도는 느리므로
메모리 블럭의 전송 단위가 비교적 커짐.
- 어찌되었든, L1 캐시에는 현재 접근 메모리 근방의 2MB 만큼의 메모리 블럭이
이미 올라가 있음. 프로그램의 spatial locality 때문에, 이 크기 안에서 캐시 힛이
발생할 확률이 높아짐. 캐시 미스는 거의 안남.
- 즉, 메모리 블럭 단위 전송이 90퍼 캐시힛의 큰 역할.

16.2-4 Cache Friendly Code
Note) 아래와 같이 작성하면, 한번 arr[i][j]에 접근하면 나머지 3번동안은
캐시 미스가 발생하지 않게됨.
... 중략 ...
int nTotal = 0;
for (size_t i = 0; i < SIZEOFARR; ++i)
{
for (size_t j = 0; j < SIZEOFARR; ++j)
{
nTotal += arr[i][j];
}
}
... 중략 ...
16.3 가상 메모리(Virtual Memory)
Prologue) 실제로 CPU가 하나의 프로그램을 실행하는데
요구하는 총 메모리 공간이 2GB라 하자.
근데 메인 메모리는 256MB가 끝임. 그럼에도 불구하고 2GB를 서비스 해주기위해,
하드 디스크와 같은 대용량 메모리를 활용함.
게다가 하드 디스크는 메모리와 다르게, 파일 시스템을 이용한 저장의 역할도 가능함.
즉, 메인 메모리를 넘어 하드 디스크까지 그 영역을 넓히는 것을 가상 메모리 기법이라 함.
16.3-1 가상 주소(Virtual Address)
Note) 가상 주소가 해결하고 있는 두 가지
- 선할당으로 인한 부담.
운영체제는 프로세스가 생성될 때마다 32bit 시스템 기준, 4GB의 메모리 공간을 할당해줌.
근데, 프로그래머가 짠 코드도 실행되어야 겠지만, 커널 코드도 실행되어야 함.
그래서 유저 영역이 2GB 정도. 이 2GB 내에는 유저 프로그램도 들어가게 됨.
유저 프로그램이 500MB라면, 나머지 2048MB-500MB 내에서 우리가 프로그램 실행중에 활용 가능.
근데 그렇다고 해서 4GB를 메인 메모리에 단 번에 선할당해주고, 아무도 접근 못하게하는게 아님.
그 사이에는 아직 안쓰는 부분도 상당히 많기 때문에 부담이 됨.
- 느린 속도의 개선
RAM이 부족하면 하드 디스크까지 확장하여서 사용한다고 언급함.
그럼 프로그램 실행 중에, RAM에 접근하는 상황이면 빠르고,
하드 디스크에 접근하는 상황에 느리다면 말이 안됨. 실제로도 그렇진 않음.
이런 부분이 문제가 될 수 있는데, 가상 메모리 기법은 위 두 문제를 해결함.

Note) 가상 주소 Vs. 물리 주소
- 메인 메모리에서 하드 디스크까지 확장하긴 했지만, 하드 디스크 영역을
실질적인 물리 주소로 바라보진 않음. 물리 주소는 RAM의 메모리 공간을 가리키는 주소.
- 만약 RAM이 256MB라면, 0번지부터 256MB - 1번지까지의 주소.
가상 메모리 기법을 도입하여, 확장된 256MB번지부터의 주소를 가상 주소라 함.
16.3-2 선 할당으로 인한 부담 해결책
Note) CPU를 손님, MMU(Memory management unit)를 종업원이라 해보자.
손님은 자신이 필요한 메모리가 충분히 있다고 생각하고 동작함.
즉, 필요한 전체 메모리가 2GB라면, 0번지부터 2GB - 1번지 모두 접근할 수도 있음.
그러나 아래 그림처럼 MMU가 중간에서 눈속임을 함.
CPU: 1KB번지부터 20B 할당 요청-> MMU: 0KB번지부터 4KB-1번지까지를 할당
이 주소는 용도가 결정남. 다른 손님 못옴.
CPU: 36KB번지부터 20B 할당 요청-> MMU: 4KB번지부터 8KB-1번지까지를 할당
이 주소는 용도가 결정남. 다른 손님 못옴.
다시 말해서, CPU는 순차적으로 메모리를 사용하고 있다고 생각하지만
MMU는 정해진 메모리 블럭 단위로 차곡차곡 용도를 결정하고 있음.

Note) 위와 같은 상태에서, CPU가 MMU에게 36KB번지의 데이터를 달라고 요청하면
MMU는 36KB번지(가상 메모리)에 매핑된
4KB번지(물리 메모리)로 가서 데이터를 가져오는 CPU에게 반환하는 방식.
Note) 페이지와 페이지 프레임의 크기는 일치함.
페이지 단위로 데이터를 할당하고 해제하기 때문.

16.3-3 느린 속도의 개선
Note) 하드 디스크의 일부까지 메인 메모리의 영역을 확장하고
이를 가상 메모리라 칭함. 그리고 RAM 부분을 실질적인 물리 메모리라 함.
근데 RAM에 접근할 때와 하드 디스크에 접근할때 속도가 다르지않음.
이를 위해서 캐시 개념을 도입하는것.
사실 전체적인 2GB의 메모리는 하드디스크에 다 있음.
temporal locality와 spatial locality에 의해서 메모리 블럭 단위로 메모리에 가져다 놓고
접근하는 방식으로 동작하면 느린 속도를 개선할 수 있음.
즉, 캐시와 RAM의 관계처럼, RAM과 하드디스크의 관계를 이해하면 됨.

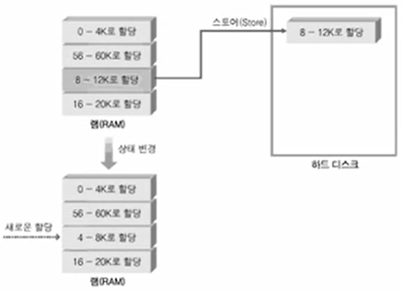
Note) 만약 프로그램 실행 중에 RAM이 꽉 찼다고 가정 해 보자.
이때 CPU가 4~8KB 구간을 쓰겠다고 요청이 들어옴.
1. 식당으로 따지면 다 먹어가는 사람, 마지막 사용 시간이 오래된 메모리를 빼냄.
왜냐면 지역성이 떨어지기 때문. 오래된 메모리는 다시 하드디스크에 저장(store)함.
2. 반대로 CPU가 8~12KB 구간을 쓰겠다고 요청하면 4~8KB 구간과 태그하는 게 아니라,
RAM에서 마지막 사용 시간이 오래된 메모리를 HDD로 저장하고, 8~12KB 구간을 load함
3. 이때 load하는 경우, File System을 이용해서 저장하게됨.
즉, 프로세스의 가상 메모리 공간 확장을 위해 생성된 파일을 일컫어 스왑파일이라 함.
다시 말하면 RAM에서 필요하다 하면 스왑파일을 올려주고, 필요 없다하면 스왑파일을 저장함
그래서 RAM 만큼이나 HDD가 중요함.

Note) 아직까지 설명 안된 부분은, 물리 메모리 주소가 어떻게 가상 메모리 주소가 되는가임.
이부분은 책에서 자세히 설명함.
16.3-4 둘 이상의 프로세스와 가상 메모리
Note) 스왑파일이 여러개 있어도 전혀 문제가 안됨.
프로세스 별로 4GB의 메모리 공간을 할당해줘야함.
아래 그림과 같이, 별도의 하드 디스크에 각각의 스왑파일을 저장하기 때문에 가능.
즉, 현재 프로세스 A가 Running 상태라면 RAM은 프로세스 A 스왑 파일과 일체되서
가상 메모리 공간을 구성하여 작업을 진행함.
아래 그림만 봐도, 프로세스가 바뀔 때마다 RAM에 있는 데이터가 비워지고 채워져야 하기 때문에
이런 작업들도 반드시 CS에 포함되어야함. 상당히 부담되는 작업.

'C > [서적] 뇌를 자극하는 윈도우즈 시프' 카테고리의 다른 글
| Chapter 18. 파일 I/O와 디렉터리 컨트롤 (0) | 2022.02.14 |
|---|---|
| Chapter 17. 구조적 예외처리(Structured Exception Handling) (0) | 2022.02.13 |
| Chapter 15. 쓰레드 풀링 (0) | 2022.02.13 |
| Chapter 14. 쓰레드 동기화 기법2 - 실행 순서 동기화 (0) | 2022.02.10 |
| Chapter 13. 쓰레드 동기화 기법1 - 임계 영역 접근 동기화 (0) | 2022.02.09 |



댓글