17.1 SEH(Structured Exception Handling)
Prologue) 우리의 컴퓨터 시스템에서 발생하는 예외라는 것이
어떤 방식으로 발생하고 처리되는가.
컴퓨터 시스템은 CPU + OS + APP으로 구성됨.
- 내부 외부를 나누는 기준은 CPU + OS를 내부, APP을 외부로 나누기도 함.
- 또는 CPU를 하드웨어, OS와 APP을 소프트웨어로 나눔.
CPU로는 명령어들이 하나씩 순차적으로 FDE됨.
이 명령어는 경우에따라 OS일수도, APP일수도있음. 다만 CPU는 이를 구분하진 못함.
전달되어진 명령어를 연산할 뿐임. OS인지 APP인지 관심없음.
다만 CPU를 디자인할때, CPU의 연산 방법은 정해져 있음.
ex. 4byte 피연산자 나누기 1byte 피연산자는 불가능.
CPU는 동일한 바이트 피연산자들끼리 연산함. CPU는 1byte 피연산자를 4byte로 강제 캐스팅.
ex. 32bit 시스템에서, 기본적인 연산의 단위는 4byte임. 이때 1byte + 1byte 가능?
RISK라면, 불가능함. 내가 아무리 char 변수 두개 더한다 한들, 내부적으론 4byte로 변환됨.
ex. 0으로 나누는것은 불가능함.
위와 같은 명령어들이 들어오면, 당최 CPU는 할 수 없으므로, 예외적인 상황으로 간주.
다시 말하면, CPU는 예외적인 상황들을 정해둠. 그리고 CPU에 올려져서 동작하는 소프트웨어
즉, OS와 APP들에게 해당 예외적인 상황이 발생했음을 알려만 줌.
후속 처리는 소프트웨어에게 맡김. 이런 후속 처리하는 코드를 핸들러라고 함.
ex. 1번 예외가 발생하면 또 다른 소프트웨어에 의해 1번 핸들러 동작함.
다만 예외 부분은 하드웨어적으로 고정되어 있음. 프로그래머가 결정할 수 없음.
핸들러는 프로그래머가 결정할 수 있음. 그럼 누가 핸들러를 만드느냐?
CPU에 OS를 이식할때 모두 설정되어 있음.
Note) Windows의 SEH
1. CPU에선 1번 예외 DIVIDE_BY_ZERO가 발생했다고 알려줌.
OS에선 OS 자신이 초래한 예외일수도, APP이 초래한 예외일수도 있음.
거의 대부분 APP이 초래 했을 확률이 높음.
2. 그럼 OS는 APP에게 1번 예외 DIVIDE_BY_ZERO가 발생했다고 알려줌.
즉, 1번 2번에 따르면 "CPU와 OS의 관계 == OS와 APP의 관계"
3. SO는 APP에게 예외 발생 여부를 알려주면서, 해당 예외를 처리할 방법도 알려줌.
이를 SEH 메커니즘이라고 함. 즉 우리가 배울 부분이 OS와 APP 사이의 SEH
Note) SEH에 의하면, OS에서도 APP단에서도 예외를 정의할 수 있음.
이를 SW 예외라고 칭함. 즉, OS단에서 예외를 정의해서
APP에게 발생여부를 전달할 수 있음.
CPU 단에서의 예외를 하드웨어 예외라고 하고,
OS 단에서의 예외를 소프트웨어 예외라 함.
또한, DIVIDE_BY_ZERO가 CPU단에서 발생해서 OS에게 알리고
OS에서 APP으로 SEH 메커니즘에 의해 전달시키게 되면 SW 예외가 됨.
17.1-1 예외 처리의 필요성
Note) 예외 처리 전 코드.
FILE* ptrFile = fopen("test.txt", "r");
if (NULL == ptrFile) // 파일이 없는 경우는 일반적이진 않음. -> 예외처리
{
// Exception Handling.
}
char* dataBuffer = (char*)malloc(sizeof(char)*100);
if (NULL == dataBuffer) // 동적할당 받을 메모리가 없는 경우는 일반적이진 않음. -> 예외처리
{
// Exception Handling.
}
int nRead = fread(dataBuffer, 1, 10, ptrFile);
if (10 != nRead) // 읽은 데이터의 갯수가 올바르지 않은 경우는 일반적이진않음.->예외처리
{
// Exception Handling.
// 추가로 파일의 끝인지, EOF(end of file)인지 비교해야 함.
}
Note) 위 코드를, 프로그램의 실제 흐름과 흐름에 대한 예외 처리 영역으로 나누고픔.
이런 정신이 SEH에 반영되어 있음. 두 영역을 나눠놓음. 이게 왜 중요할까?
위 코드에서 조건문들이 예외를 위한 블럭인지, 프로그램의 메인 로직의 하나인지 모름.
그래서 무작정 일단 읽어봐야함. 예외적인 코드라도 다 읽어야함.
전체적인 흐름만 알고 싶더라도 그래야함. 그래서 SEH는 코드의 가독성에 많은 도움을 줌.
// 프로그램의 실제 흐름
FILE* ptrFile = fopen("test.txt", "r");
char* dataBuffer = (char*)malloc(sizeof(char)*100);
int nRead = fread(dataBuffer, 1, 10, ptrFile);// 위 흐름에 대한 예외 처리 영역
if (NULL == ptrFile)
{
// Exception Handling.
}
if (NULL == dataBuffer)
{
// Exception Handling.
}
if (10 != nRead)
{
// Exception Handling.
}
17.1-2 예외와 에러의 차이점
Note) 컴파일 타임 오류: 에러(문법적 구문 오류. 큰 실수.)
- 에러는 고쳐야 함.
Note) 런 타임 오류: 일반적으로 예외(실수는 다 잡아낸 상태.)
- 예외는 처리되어야 함.
- ex. 프로그램을 사용하려면 특정 파일이 있어야 하는데,
사용자가 해당 파일을 준비해두지 않은 상황.
예외 같이, 프로그램의 잘못이 아니라, 소프트웨어의 일반적인 환경을
벗어난 상황을 의미함. 좋은 소프트웨어는 이에 대해 잘 대비되어 있음.
특정 프로그램의 경우(서버)에는 예외 처리가 잘되어야만 함.
Note) 우리의 관심사는 결국 에러가아니라 예외임.
이를 어떻게 처리할것이냐? SEH 메커니즘을 통해서 유연하게 처리할 예정.
17.1-3 하드웨어 예외(CPU)와 소프트웨어 예외(OS+APP)
Note) 하드웨어 예외
- 하드웨어에서 문제시 삼는 상황
- 예로 0으로 정수를 나누는 행위
Note) 소프트웨어 예외
- 운영체제 개발자나, 프로그래머가 정의한 예외
Note) SEH 메커니즘 동작
- 소프트웨어 예외 발생시 Windows는 예외 처리 메커니즘을 동작시킴.
- 하드웨어 예외 발생시에도 Windows에 의해 인식되어
예외 처리 메커니즘이 동작됨.
Note) 예외 핸들러가 있고 종료 핸들러가 있음.
- SEH에는 예외 핸들러 개념을 활용해서
소프트웨어를 좀 더 안정적으로 개발할 수 있음.
17.2 종료 핸들러(Termination Handler)
17.2-1 종료 핸들러의 기본 구성과 동작 원리
Note) __try 블럭에 진입하게되면, 어떤일이 있어도 __finally 블럭도 실행되게됨.
__try
{
// 예외 발생 경계 블럭
... 중략 ...
}
__finally
{
// 종료 처리 블럭
... 중략 ...
}
Note) 실제 개발 예.
... 중략 ...
__try
{
_tprintf(_T("Input divide string [a / b]: "));
_tscanf(_T("%d / %d", &a, &b));
if (0 == b) { return -1; } // return 한다해도 무조건 __finally 블럭 진입.
}
__finally
{
_tprintf(_T("In __finally block.\n"));
}
_tprintf(_T("result: %d\n", a / b));
... 중략 ...
17.2-2 종료 핸들러 활용 사례
Note)
__try
{
ptrFile = _tfopen(_T("string.dat"), _T("a+t"));
if (NULL == ptrFile)
{
DWORD strLen = 0;
return -1;
}
strBuffer = (TCHAR*)malloc((strLen + 1) * sizeof(TCHAR));
if (NULL == strBuffer)
{
return -1;
}
... 중략 ...
}
__finally
{
if (NULL != ptrFile)
{
fclose(ptrFile); // 파일을 열었기에 반드시 닫아줌.
}
if (NULL != strBuffer)
{
free(strBuffer); // 동적할당 받았기에 반드시 해제 해줘야함.
strBuffer = NULL;
}
}
17.3 예외 핸들러(Exception Handler)
17.3-1 예외 핸들러와 필터
Note) __try 블럭에서 발생한 예외는 그 뒤에 나오는 __except 블럭에서 처리
그 예외처리 방식에는 크게 세 가지로 나뉨. 이런 예외 처리 방식을 필터라고 함.
약간 switch-case와 유사한 방식임.
__try 블럭에서 예외가 발생하면, OS가 __except 블럭으로 진입시킴은 물론
필터까지 확인해서 그에 맞게 동작하게됨. 이것이 SEH 메커니즘.

17.3-2 EXCEPTION_EXECUTE_HANDLER
Note) 예외 발생 직후의 나머지 문장을 생략함.

17.3-3 EXCEPTION_EXECUTE_HANDLER 사례연구
Note)
__try
{
switch(sel)
{
... 중략 ...
case DIV:
result = num1 / num2; // 여기서 끊고 __except 블럭으로 넘어감. 뒤는 의미없음.
_tprintf(_T("%d / %d = %d\n\n"), num1, num2, num1/num2);
break;
... 중략 ...
}
}
__except(EXCEPTION_EXECUTE_HANDLER)
{
_tprintf(_T("Wrong number inserted. Try again!\n\n"));
}
17.3-4 처리되지 않은 예외의 이동
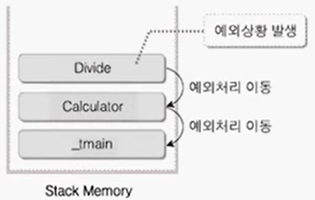
Note) 아래 그림의 시나리오.
1. Divide() 함수 내에서 DIVIDE_BY_ZERO 예외가 H/W에서 발생.
2. H/W는 OS에 예외 발생 알림. Windows는 SEH 메커니즘 동작.
3. 그러나, DIVIDE_BY_ZERO 예외가 발생한 지점이 __try 블럭으로 묶여있지 않음.
SEH에서는 예외 처리가 되지 않을 시에, 예외가 발생한 함수를 콜스택에서 꺼내버리고,
함수 콜스택의 역순으로 예외를 전달함.
4. 그럼 다시 Calculator() 함수로 돌아왔더니, 예외처리가 되어 있어서 정상 처리.
5. 만약 Calculator() 함수도, _tmain() 함수도 제대로 처리하지 않는다면 OS에게로 넘어감.
그럼 OS는 예외처리를 제대로 하지 않은 프로세스로 간주하고 프로세스를 강종함.
이게 처리되지 않은 예외의 이동.

17.3-5 예외를 구분하는 방법
Note) GetExceptionCode() 함수
- 호출 가능 위치
__exception 블럭 내 / 예외필터 표현식 지정 위치
이외에는 의미가 없음. 예외가 발생하지않을수도 있는 위치기 때문.
- 반환 값의 예
EXCEPTION_STACK_OVERFLOW
EXCEPTION_INT_DIVIDE_BY_ZERO
MSDN 참조.
Note)
__try
{
... 중략 ...
}
__except(EXCEPTION_EXECUTE_HANDLER)
{
DWORD exceptionType = GetExceptionCode();
switch(exceptionType)
{
case EXCEPTION_ACCESS_VIOLATION:
_tprintf(_T("Access violation\n\n"));
break;
case EXCEPTION_INT_DIVIDE_BY_ZERO:
_tprintf(_T("Divide by zero\n\n"));
break;
}
}
17.3-6 EXCEPTION_CONTINUE_EXECUTION
Note) __except 블럭을 실행하지 않고, 예외가 발생한 지점에서부터 다시 실행.
ex. DIVIDE_BY_ZERO 예외의 경우에 값을 하나 더 받아서, 다시 실행하면 됨.
Note) 관련예제 Ex17-10을 모델로하여 활용 용도를 파악.
17.3-7 EXCEPTION_CONTINUE_SEARCH
Note) 예외를 적절히 처리안하면, 해당 함수는 강제로 콜스택에서 팝되버림.
EXCEPTION_CONTINUE_SEARCH는 그냥 배째라. 그렇게 하라는 식.
콜리쪽으로 돌아가서, 예외가 발생한 위치와 예외처리하는 위치를 달리하기 위함.
잘 안쓰임.

'C > [서적] 뇌를 자극하는 윈도우즈 시프' 카테고리의 다른 글
| Chapter 19. 비동기 I/O와 APC (0) | 2022.02.14 |
|---|---|
| Chapter 18. 파일 I/O와 디렉터리 컨트롤 (0) | 2022.02.14 |
| Chapter 16. 컴퓨터 구조에 대한 네 번째 이야기 (0) | 2022.02.13 |
| Chapter 15. 쓰레드 풀링 (0) | 2022.02.13 |
| Chapter 14. 쓰레드 동기화 기법2 - 실행 순서 동기화 (0) | 2022.02.10 |



댓글